Quality Diversity through Human Feedback:
Towards Open-Ended Diversity-Driven Optimization
ICML 2024
NeurIPS 2023: ALOE Workshop (Spotlight)
-
Li Ding
UMass Amherst
-
Jenny Zhang
Univ. of British Columbia
Vector Institute
-
Jeff Clune
Univ. of British Columbia
Vector Institute
Canada CIFAR AI Chair
-
Lee Spector
Amherst College
UMass Amherst
-
Joel Lehman
Stochastic Labs
(Work done at Stability AI)
QDHF (right) improves the diversity in text-to-image generation results compared to best-of-N (left) using Stable Diffusion.
Abstract
Reinforcement Learning from Human Feedback (RLHF) has shown potential in qualitative tasks where easily defined performance measures are lacking. However, there are drawbacks when RLHF is commonly used to optimize for average human preferences, especially in generative tasks that demand diverse model responses. Meanwhile, Quality Diversity (QD) algorithms excel at identifying diverse and high-quality solutions but often rely on manually crafted diversity metrics. This paper introduces Quality Diversity through Human Feedback (QDHF), a novel approach that progressively infers diversity metrics from human judgments of similarity among solutions, thereby enhancing the applicability and effectiveness of QD algorithms in complex and open-ended domains. Empirical studies show that QDHF significantly outperforms state-of-the-art methods in automatic diversity discovery and matches the efficacy of QD with manually crafted diversity metrics on standard benchmarks in robotics and reinforcement learning. Notably, in open-ended generative tasks, QDHF substantially enhances the diversity of text-to-image generation from a diffusion model and is more favorably received in user studies. We conclude by analyzing QDHF's scalability, robustness, and quality of derived diversity metrics, emphasizing its strength in open-ended optimization tasks. Code and tutorials are available at https://liding.info/qdhf.
Method
The main idea is to derive distinct representations of what humans find interestingly different, and
incorporate this procedure in QD algorithms.
- Diversity Characterization: A latent projection is used to model representations of diversity as its measures.
- Alignment: We use contrastive learning to align the diversity representations to human intuition.
- Progressive Optimization: As novel solutions are found, more human feedback is collected to refine the diversity representation.
Robotic/RL (Policy Search)
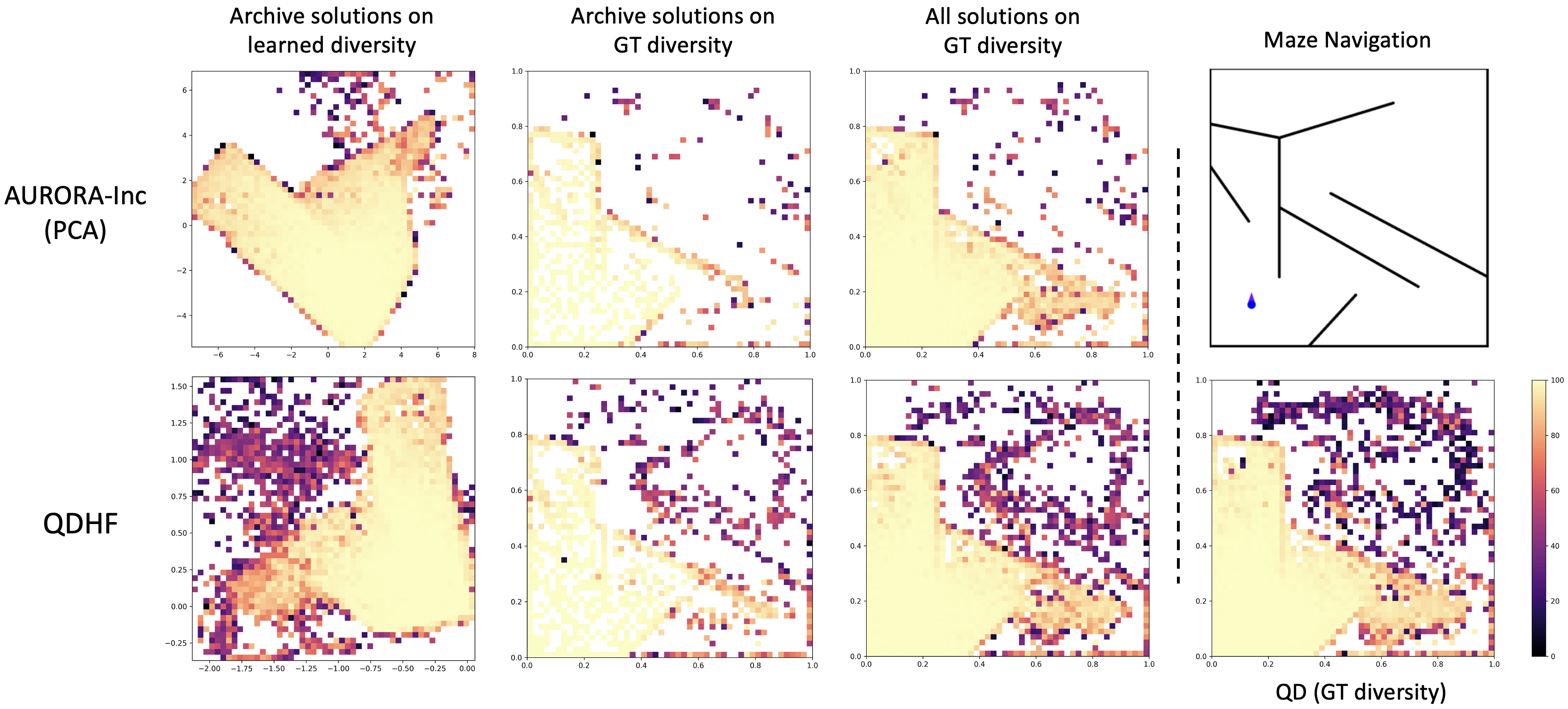
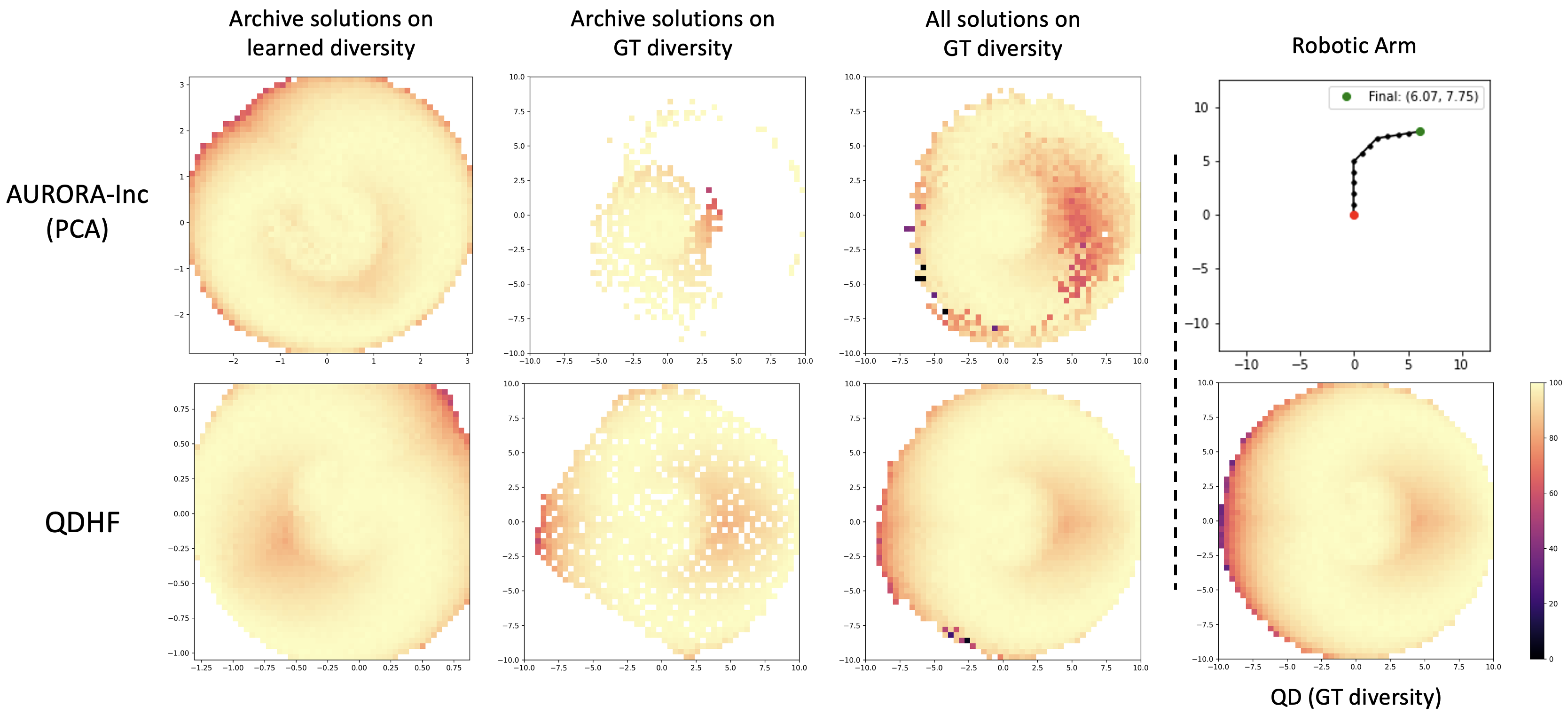
Each point on the heatmap is a solution with its objective
value visualized in color. QDHF fills up the archives with more solutions than AURORA, and closely
matches the search performance of QD using the ground truth diversity metrics.
Notably, in the maze navigation task, while both
AURORA and QDHF learned a rotated version of the maze as diversity (first column), QDHF is
able to more accurately learn the scale of the maze especially in the under-explored area.
Open-Ended Generation (Latent Space Illumination)






QDHF substantially enhances the variations in images generated by a diffusion model. The results show visible trends of diversity, and was more favorably received in user studies.
Citation
Acknowledgements
Li Ding and Lee Spector were supported by the National Science Foundation under Grant No. 2117377.
Jeff Clune and Jenny Zhang were supported by the Vector Institute, a grant from Schmidt Futures, an NSERC
Discovery Grant, and a generous donation from Rafael Cosman. Any opinions, findings, and conclusions or
recommendations expressed in this publication are those of the authors and do not necessarily reflect the
views of the funding agencies.
The authors would like to thank Andrew Dai and Herbie Bradley for insightful suggestions, Bryon Tjanaka for
help preparing the tutorial, members of the PUSH lab at Amherst College, University of Massachusetts
Amherst, and Hampshire College for helpful discussions, and anonymous reviewers for their thoughtful
feedback.
This work utilized resources from Unity, a collaborative, multi-institutional high-performance computing
cluster at the Massachusetts Green High Performance Computing Center (MGHPCC).
The website template was borrowed from Jon
Barron.